Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world. So rather than hand-coding software routines with a specific set of instructions to accomplish a particular task, the machine is “trained” using large amounts of data and algorithms that give it the ability to learn how to perform the task.
As it turned out, one of the very best application areas for machine learning for many years was computer vision, though it still required a great deal of hand-coding to get the job done. People would go in and write hand-coded classifiers like edge detection filters so the program could identify where an object started and stopped; shape detection to determine if it had eight sides; a classifier to recognize the letters “S-T-O-P.” From all those hand-coded classifiers they would develop algorithms to make sense of the image and “learn” to determine whether it was a stop sign.
Good, but not mind-bendingly great. Especially on a foggy day when the sign isn’t perfectly visible, or a tree obscures part of it. There’s a reason computer vision and image detection didn’t come close to rivaling humans until very recently, it was too brittle and too prone to error. [1]
Machine learning is a field of computer science that gives computers the ability to learn without being explicitly programmed.[2]
Types of problems and tasks
Machine learning tasks are typically classified into three broad categories, depending on the nature of the learning "signal" or "feedback" available to a learning system. These are
- Supervised learning: The computer is presented with example inputs and their desired outputs, given by a "teacher", and the goal is to learn a general rule that maps inputs to outputs. Most common form Machine Learning. Right answers are given to dataset.
- Unsupervised learning: No labels are given to the learning algorithm, leaving it on its own to find structure in its input. Unsupervised learning can be a goal in itself (discovering hidden patterns in data) or a means towards an end (feature learning).
- Reinforcement learning: A computer program interacts with a dynamic environment in which it must perform a certain goal (such as driving a vehicle or playing a game against an opponent). The program is provided feedback in terms of rewards and punishments as it navigates its problem space.
Supervised Learning[5]
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
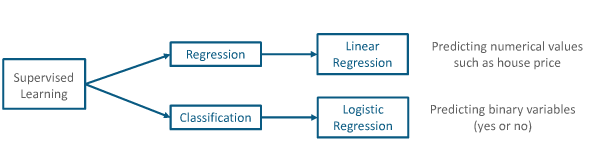
Supervised learning problems are categorized into "regression" and "classification" problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
Example:
(a) Regression - Given a picture of a person, we have to predict their age on the basis of the given picture
(b) Classification - Given a patient with a tumor, we have to predict whether the tumor is malignant or benign.
Unsupervised Learning
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don't necessarily know the effect of the variables. Clustering Algorithm.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results.
Example:
Clustering: Take a collection of 1,000,000 different genes, and find a way to automatically group these genes into groups that are somehow similar or related by different variables, such as lifespan, location, roles, and so on.
Non-clustering: The "Cocktail Party Algorithm", allows you to find structure in a chaotic environment. (i.e. identifying individual voices and music from a mesh of sounds at a cocktail party).

The two tasks of supervised learning: regression and classification
Regression: predict a continuous numerical value. How much will that house sell for?
Classification: assign a label. Is this a picture of a cat or a dog?
Predictive Models
We can choose many models, each based on a set of different assumptions regarding the underlying distribution of data. Therefore, we are interested in two general types of problems in this discussion: 1. Classification—about predicting a category (a value that is discrete, finite with no ordering implied), and 2. Regression—about predicting a numeric quantity (a value that's continuous and infinite with ordering).
Linear Regression [4]
Linear regression has the longest, most well-understood history in statistics, and is the most popular machine learning model. It is based on the assumption that a linear relationship exists between the input and output variables, as follows:

…where y is the output numeric value, and xi is the input numeric value.
The learning algorithm will learn the set of parameters such that the sum of square error (yactual- yestimate)2is minimized. Here is the sample code that uses the R language to predict the output "prestige" from a set of input variables
Predicting income is a classic regression problem. Yourinput data Xincludes all relevant information about individuals in the data set that can be used to predict income, such as years of education, years of work experience, job title, or zip code. These attributes are calledfeatures, which can benumerical(e.g. years of work experience) orcategorical(e.g. job title or field of study).
You’ll want as many training observations as possible relating these features to the target output Y, so that your model can learn the relationship_f_between X and Y.
Neural Network [4]
A Neural Network emulates the structure of a human brain as a network of neurons that are interconnected to each other. Each neuron is technically equivalent to a logistic regression unit.
K-Nearest Neighbors [4]
A contrast to model-based learning is K-Nearest neighbor. This is also called instance-based learning because it doesn't even learn a single model. The training process involves memorizing all the training data. To predict a new data point, we found the closest K (a tunable parameter) neighbors from the training set and let them vote for the final prediction.
